Speaker Classification
ABRAHAM HOLLERAN & CAMERON ABBOT
Context
We have conversations every day, whether through verbal speech, email threads, text messages, or some other medium. In all these things, our speech has distinct attributes: our word choice, style of speech, lengths, etc. We sought to use these (primarily word choice) to make a model that predicts who authored a specific message, given a set of data between labeled authors.
Our concept is broad, which allows us flexibility with the direction we want to go with our models. The responsibility of the model is kept at a high level: to take in a set of dialogues labeled with their respective speakers, and use that to be able to predict the speaker of a given string of text. This is natural language processing (NLP), a step in difficulty above regression or simple classifications. The applications that this allows are specific, and we focused on two in particular that we will discuss here. We first examined the 2020 presidential debates and developed a model to determine which candidate or moderator said a particular statement. We then were able to downscale this same model to sets of text messages between two individuals. With this, one would be able to input a particular text message and the model should return who was most likely to have written it.
Reading in Data
A critical step of this process was finding an efficient way of reading in and processing text data. For the sms data, we used the SMS Backup and Restore app for Android to extract an xml data file for a single conversation, a process that can be consistently and quickly reapplied to retrieve new data; having our end goal of deployment and ease-of-use for the user in mind helped us think this through. The xml file is processed using the Pandas Read XML tool, and then a few commands extract the desired dataframe from the xml.
Attempted Strategies
- Basic feature engineering with Logistic Regression
We started simple, and took the approach of seeing how accurately we might be able to predict authorship based on some basic features of the text.
However, this did not produce results of any notable significance, since the correlations between these engineered features and the author were too low. Punctuation was the most correlated, at 22%, but this was still not sufficient.
2. Neural Networks
We also tried Neural Networks and also got unsatisfactory results. In order to give the NN numerical data, we used a bag of words approach (see below) but found data in this format difficult to work with. In this example, we used the second debate, which had 280 speech snippets to train with and 70 to test with. There were 3 people speaking.
We found a testing accuracy of 32.4%, which is bad because guessing would give 33.3% accuracy. The NN was “doing something” though, because we did get 51% training accuracy. We ended up abandoning the NN approach because people, namely Navoneel Chakrabarty from this useful article, were using Naive Bayes for similar things and getting better results.
3. Multiclass Naive Bayes
This is what we ended up sticking with. This method counts the frequency of each word said in the training set to get a sense for each person’s word usage. It then predicts on some text by going through each word and summing the probability each word was said by each person.
Classification Process (using Bag of Words)
Our final process can be broken down into the following steps, and we’ll walk through the stages. The steps are loading in the data, processing the text, visualizing the data in a word cloud, creating a bag of words, training the data with this bag, and finally testing.
- Loading in Data
The first task is reading in the data file. XML files are a bit more difficult to work with and require the Pandas Read XML tool to be installed, but this process converts the data from raw xml format to a neat Pandas dataframe.
We didn’t want an imbalance of data samples. If one person talks 95% of the time, we don’t want the model to learn to always predict that person to achieve an easy 95% accuracy. To fix this, we counted up who said each message and took the minimum of both counts. We then took that many of each speaker’s speeches to assure there were equal speeches between the two. We didn’t do this on the debate data because it’s too small to cut and retain accuracy.
2. Text Processing
We improved on this by removing stopwords (common words unlikely to be preferred by one person or the other) and by a process known as stemming. For instance, the words ‘walk’, ‘walked’, ‘walks’ or ‘walking’ might come up in your text corpus. These would all be reduced to their stem, ‘walk’ to reduce the number of features. We also lemmatized the corpus by reducing words to their lemma. For instance, “better” reduces to “good.”
Also, we encoded the labels from strings to integers.
Examples of the stopwords removed are ‘i’, ‘me’, ‘my’, ‘myself’, ‘we’, ‘yours’, ‘Such’, ‘no’, ‘nor’, ‘not’, ‘only’, ‘own’, ‘same’.
3. Visualizing in a Word Cloud
To visualize these frequencies, we made word clouds.
What we noticed from these is that Chris Wallace says “Sir” the most, because that was how he chose to interject. Both moderators said “Vice President”, “President Trump” etc. frequently. Biden used the word “fact” and “he” frequently. This shows his campaign emphasis: one, that Biden has the “facts” and the “science” behind him, and two, that I am better than “he.” If you look hard enough, you can find “shut” and “man” on his collar. Trump, on the other hand, used the strong, forceful words “know”, “want” and “would” frequently. I find “would” interesting, because it implies that there are a lot of “If… would/wouldn’t” statements, so maybe Trump is blaming things on conditionals, or making conditional promises. He also says “Joe” frequently.
Below are the example word clouds created using the message chat data.
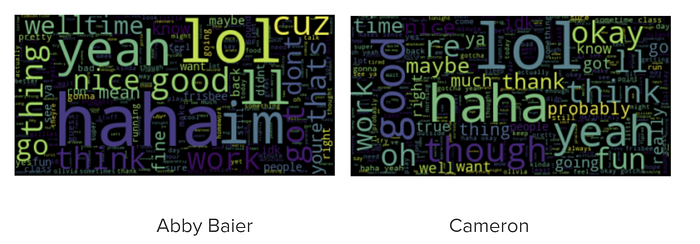
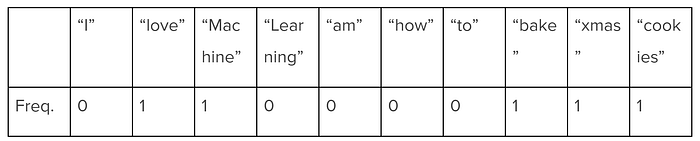
3. Converting to a Bag of words
Before we trained it, we put the data in a “bag of words” format. This is a numerical list of how many times each word was used. The total corpus (in this case, “I love machine learning” and “I am learning how to bake xmas cookies”) create the index for the list. For the phrase “Machines love baking xmas cookies,” the bag of words would be the following list.
4. Training
We tried a few classifiers.
5. Testing
Multinomial Naive Bayes resulted in the best testing score of .705. It had a training score of .853. Random forest overfit and had a training score of .979.
When we plot this as a confusion matrix, with columns as predicted values and rows as true values, we get:
Normalized over the rows and colored, this is:
Which we found to be high and satisfactory values, considering the complexity of NLP and the number of classes. One takeaway is that Trump has words only he uses, because a prediction of Trump has the highest likelihood to be true (recall).
Welker and Biden have the most unique language as they are predicted with the highest precision.
Deployment
We deployed these onto streamlit. The moderators were removed from the debate data to make a Trump/Biden classifier, which had 79% accuracy and the following confusion matrix.
Some changes to the original code had to be made and some adjustments to the program structure, but the below image shows how the deployed model allows a user to input their own data file to train the model, and then input particular lines of text to predict who authored them.
Text Classification Deployment on Streamlit
Reflections and Opportunities for Further Development
There are many ways the models can be enhanced purely structurally. One way is using phrases from the text, instead of just words from the text, using n-grams. Also, there are other features that we might engineer, such as punctuation or sentence length, that could be coupled with the existing models using ensembling methods to improve its accuracy.
Beyond the usual continued enhancement of our models, one particular way we could see progress made with this is a live deployment to be able to train and test effectively with a lot of different data, and thereby be able to push the model to its limits in terms of versatility. The deployed model can be hosted online to allow users to upload their own data and learn from it.
There are also many ways more data could be drawn from this model and delivered to the user. For example, we could output the most common 100 words with their frequencies, or we might find the words that are most distinct to each respective author. We could also very quickly retrieve the average sentence and word lengths for each, etc. There are many directions this might go, and that is the beauty of a broad model with specifically tested applications.
Notes
See our deployed Streamlit model here: share.streamlit.io/stonepaw90/chat-classification/main/chat_classification.py
See our ‘Chat Classification’ Colabs notebook here: bit.ly/chat-classification
See our ‘Debate Classifier’ Colabs notebook here: bit.ly/debate-classifier
A good deal of our final modeling techniques came from Ivan Pereira’s work here in the article “Text Classification with Pandas & Scikit — GoTrained Python Tutorials”